introduction | devel | download | cvs | docs | mailing lists | resources
mirrors | freshmeat | sourceforge
introduction | devel | download | cvs | docs | mailing lists | resources
mirrors | freshmeat | sourceforge
2002-10-03
The rproxy project is inactive.
It now seems that the effort to get rsync-in-HTTP widely adopted is not justified giving the increasing availability of high-bandwidth connections, and the decreasing fraction of web traffic that is suitable for delta-compression.
The librsync library which was developed as part of the project seems to have a more generally useful future. It is likely to power the possible new major revision of rsync. Early steps towards that are visible in Wayne's rzync prototype, and Martin's superlifter design.
If you're interested in developing the project then please go ahead and feel free to contact mbp at samba.org.
Caches are used to good effect on today's web to improve response times and reduce network usage. For any given resource, such as an HTML page or an image, the client remembers the last instance it retrieved, and it may use it to satisfy future requests. However, the current-system is all-or-nothing: the resource must either be exactly the same as the cached instance, or it is downloaded from scratch.
The web is moving towards dynamic content: many pages are assembled from databases or are customized for each visitor. In the existing HTTP caching system, this means that many resources cannot be cached at all.
A far better approach would be for the server to download a description of the changes from the old instance to the new one: a `diff' or `delta'.
Some people have proposed that the server should send the resource as an unchanging template plus variable values, or that the server should retain all old instances and so calculate the differences. These techniques have some value, but they constrain the server-side developer and seem unlikely to be widely adopted.
The rproxy extensions to HTTP allow the server to generate a diff relative to the cached instance in a way that is completely general, and transparent to both the server and user agent.
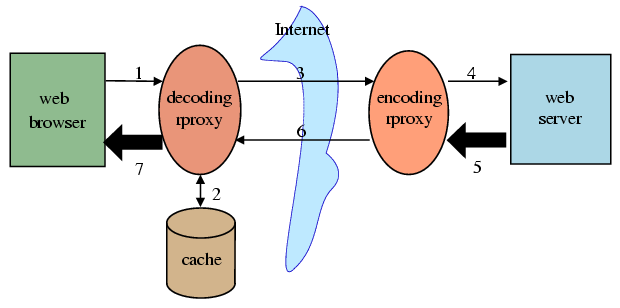
rproxy adds backwards-compatible extensions to HTTP that come into operation when two parties to a web request understand the `hsync' encoding. If there are no two that can handle these extensions then they are silently ignored, so that the software will interoperate smoothly with existing systems. These parties might be the user agent (browser), the origin server, or intermediate proxies. At this stage of the project special-purpose proxies are used so that neither the server nor user-agent need be changed, but we expect to integrate this extension into popular web software in the near future.
When an rproxy-enabled client requests a resource, it first checks whether it has a cached copy of the resource from a previous request. If it does, then it finds a block-by-block signature of the file, by computing a checksum over consecutive extents of equal length, such as 1024 bytes. The client adds this checksum into a header of the request and transmits the request as usual.
When an rproxy-enabled server receives a request containing a signature, it proceeds to generate the response, perhaps by running a server-side script. It then searches through the new instance body for blocks that have checksums that match those of blocks in the signature from the client. When it finds a match, it decides that the block is repeated from the old instance. Using this information, it generates a diff composed of instructions to copy sections from the old file, and instructions to insert new literal data. In fact, encoding can be performed inline as the response is generated, so large responses can be handled equally well.
The search for matching blocks obviously has to be able to cope with blocks that don't start on aligned boundaries, or it would not be useful in the common case where data is inserted or removed. The algorithm addresses this by supplying for this block both a `weak' CRC checksum, and a `strong' MD4 hash. The weak checksum algorithm is such that the server can efficiently check for a match at every byte offset. If a match is found, then the strong checksum is compared. If both match, the probability is astronomically high that the blocks are in fact identical.
The server also generates and sends down the signature of the new instance. The client is required to store this signature and return it on any future requests in which it wishes to use the cached instance. This mechanism will allow the differencing algorithm to be enhanced in the future without changing the client software.
The rproxy algorithm is based on the well-known and trustworthy rsync software by Andrew Tridgell.
An early implementation of rproxy achieved bandwidth savings on the order of 90% for portal web sites.
Our plans for the future are to
Copyright (C) 1999-2001 by Martin Pool unless otherwise noted.
$Id: index.latte,v 1.5 2002/10/03 07:58:07 mbp Exp $
rproxy is fed and clothed by
Linuxcare OzLabs, and
sleeps on the sofa at SourceForge.
![]()